배경 : Devocean - 블로그 사이트에 있는 KIDO 님의 SpringBatch 연재 시리즈를 직접 하나하나 따라해보면서, 스프링배치의 기초를 닦아나가보자 (스터디)
방식 : 해당 연재글 내용에서 내가 스스로 모르거나 공부한 내용을 추가 첨부해 나가는 방식으로 진행한다.
(해당 내용은 추후 github 또는 한군데 모아놓는 형태로 진행한다 - 우리만의 스프링배치 교재 처럼)
[SpringBatch 연재 01] SpringBatch 빠르게 시작하기
devocean.sk.com
내용
1. Spring Batch 초기화 및 스프링배치 필요정보
기본 프로젝트 구성하기
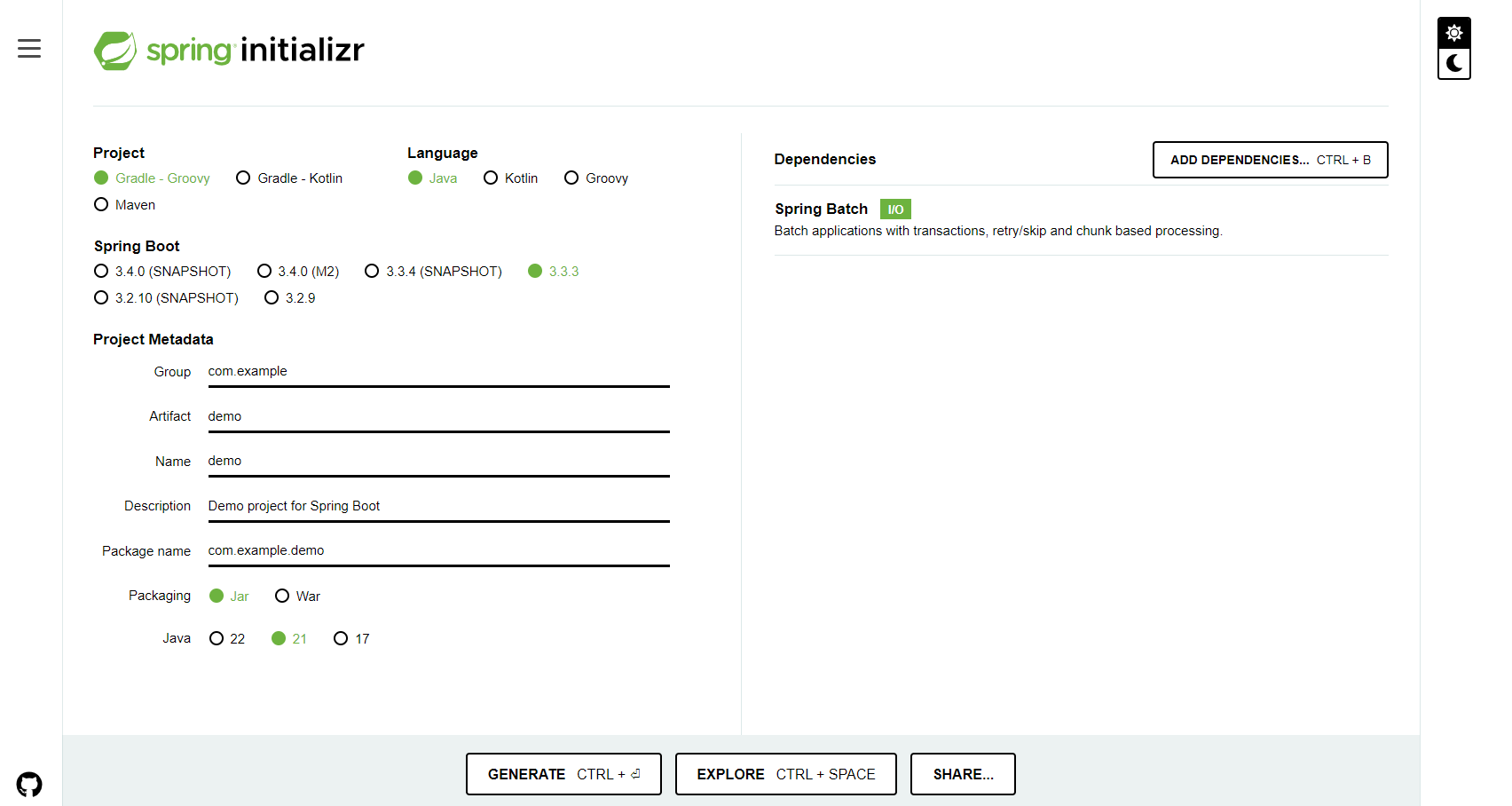
https://start.spring.io 에서 기본프로젝트 설정
(메인 연재글에는 Gradle, boot 3.2.2, Java, jdk 17 로 했음)
작성일 기준 위 사이트에는 버전이 업그레이드 되어있음. (240901 기준 아래 값으로 진행한다)
하단 GENERATE 버튼을 클릭하면 batch-sample.zip 파일을 다운로드 받을 수 있다.

[참고, TODO ] - 내가 현재 업무에서 쓰고 있는 것은 SpringBoot 1.5.22 를 사용하고 있다. 그에 맞는 스프링배치 버전은 4.1.x 라고 한다. (spring boot 1.5.x 는 spring framework 4.x와 함께 사용) 현재 사용 버전에 맞추어 사용하면 부트와 배치간 호환성 문제가 최소화되고, 안정적인 구성을 할 수 있다.
일반적으로 IDE툴 로는 프로젝트 초기 구조 설정을 만들었으나, 지금은 start.spring.io 통하하여 프로젝트 import를 해보자
(난 인텔리제이 한글이라 다들에게 도움이안될듯 ㅠㅠ)
인텔리J 실행후 --> 새로만들기 --> 기존 소스에 있는 프로젝트 클릭 --> 압축 푼 파일 경로 선택하고 확인
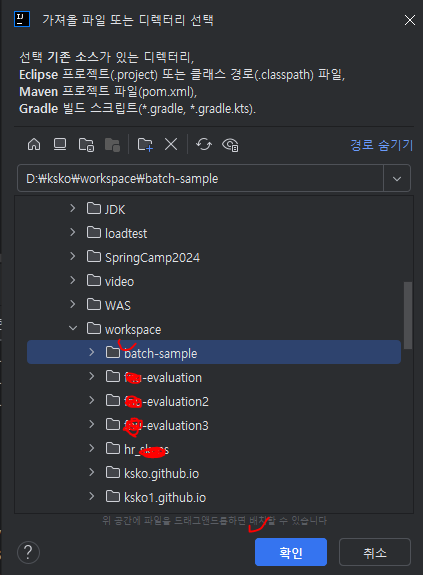
확인 누르면 팝업이 또 뜨는데, Gradle 선택, 외부 모델에서 프로젝트 가져오기 선택 후 생성 버튼 클릭

새창에서 열면 아래와 같이 보이게 된다.
하 역시 오류가 났다.. 아래 보자

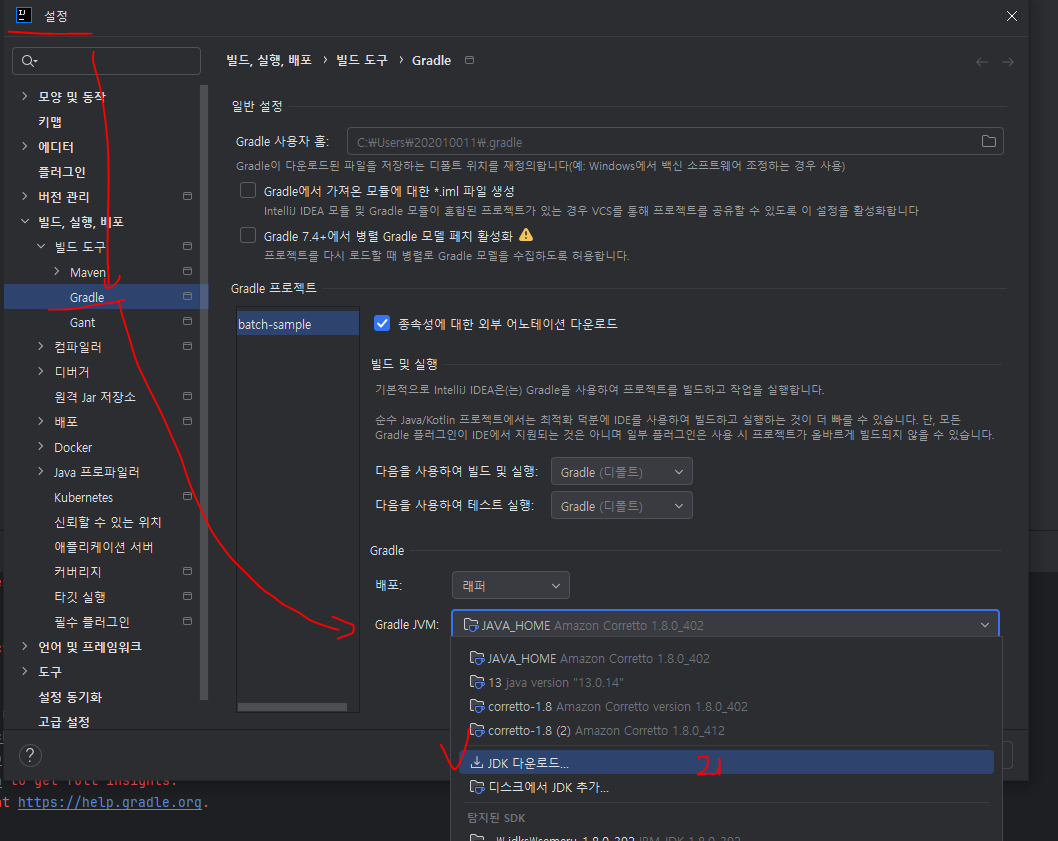
JDK 버전 연결을 프로젝트 내에서 해줘야 하는 것 같다.
인텔리제이 --> 프로젝트 삼발이 클릭 --> 설정 클릭 --> 빌드 검색후 하단 Gradle 클릭 --> 해당 화면내 Gradle 프로젝트의 JDK 버전을 맞추어준다. 21버전을 다운로드 해준다.
JDK는 뭐를 해도 크게 생관없지만 일단
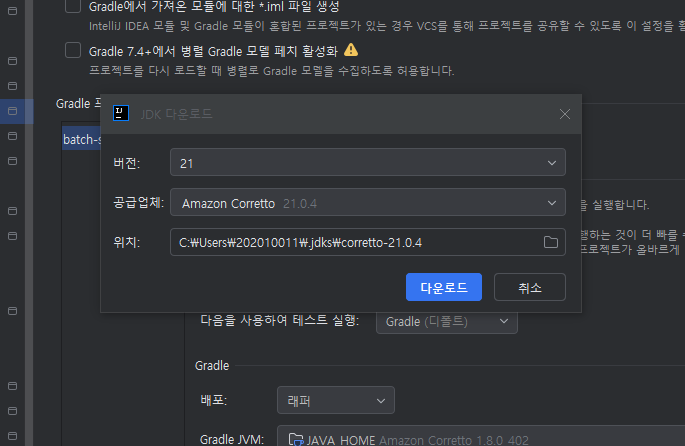
위 작업을 마치고
본래 연재 소스로 가서, 따라해보자
배치를 위한 기본 설정
build.gradle
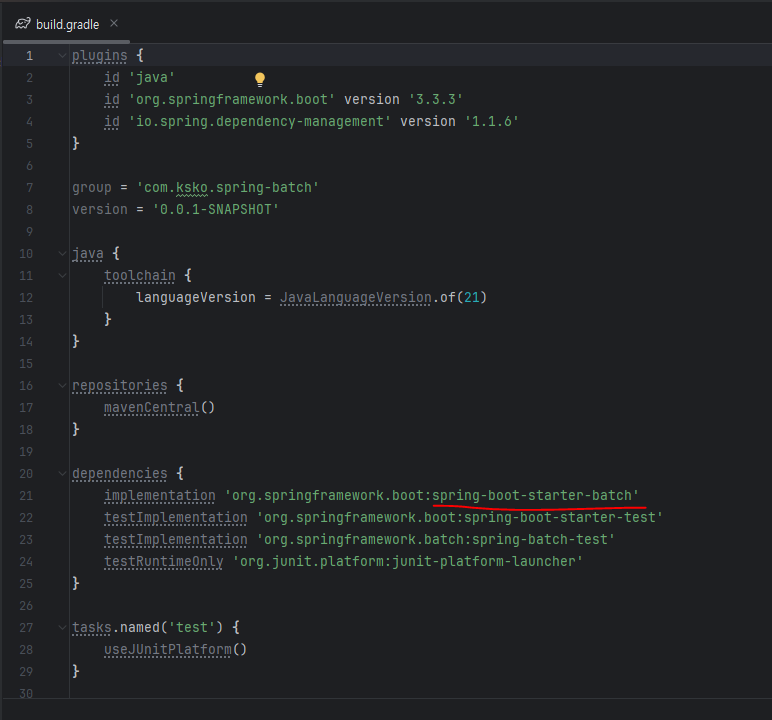
연재 글과 같이 spring-boot-starter-batch 라는 의존성 파일이 추가되어있음을 확인하였다.
배치 기동시키기
BatchSampleApplication.java 파일 내 @EnableBatchProcessing 어노테이션을 넣어보자 그냥 넣으면 안되지, 프로젝트를 Gradle 빌드를 한번 해준다.
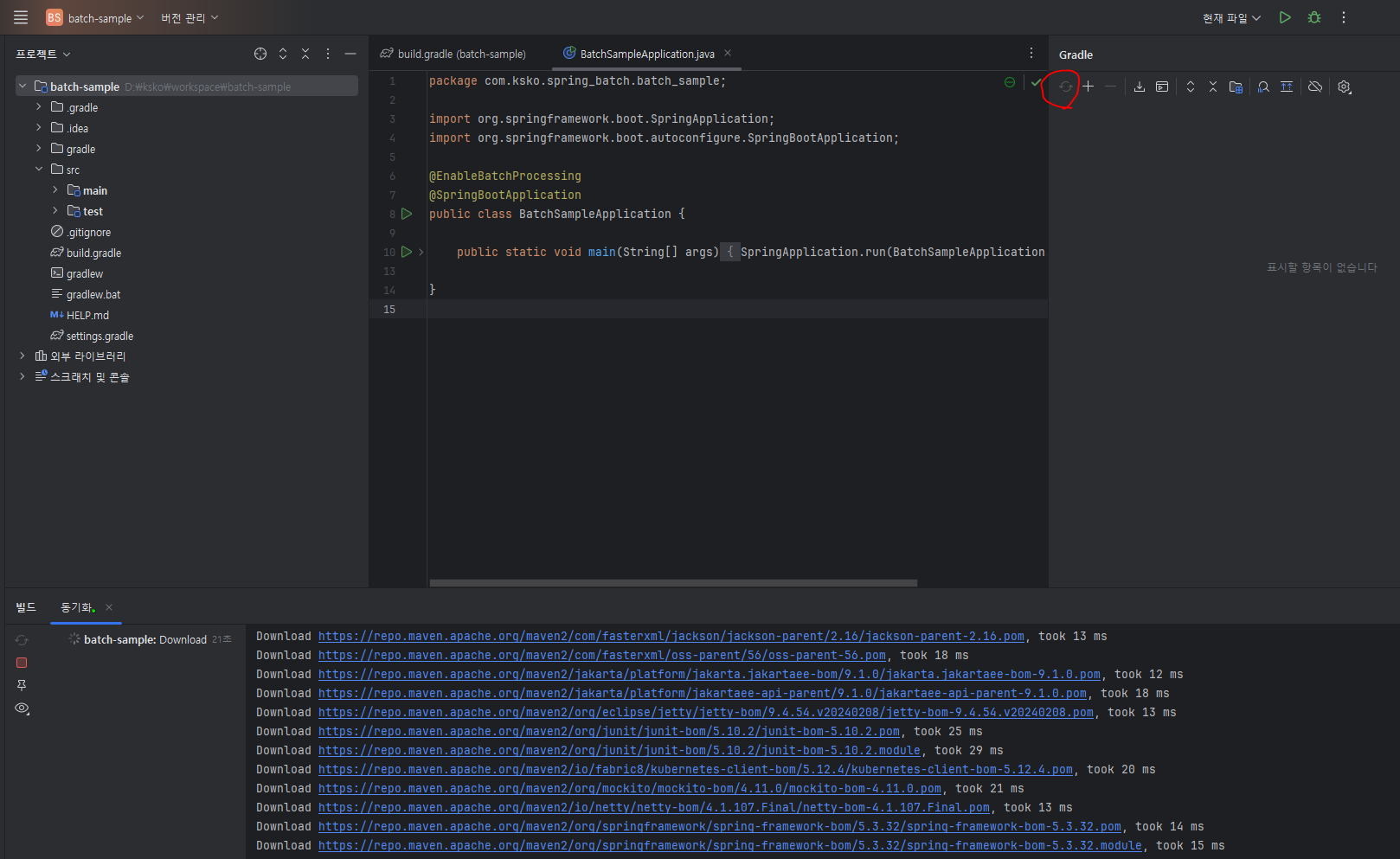
빌드 후 위 어노테이션을 다시 넣어주면 자동완성되서 촥 들어간다.

실행해보기
프로젝트를 실행해보자. gradle : bootRun 명령을 하라는데, 어디서 하라는건지 모르겟다.
(이런게 기본기가 딸려서 그런거다 ㅠㅠ)
인텔리제이 상에서 프로젝트 실행을 눌러서 위를 대체 했다
기존 교안에 나온 내용 처럼 스프링배치에서 실행할 DataSource가 필요하고, DataSource를 위한 기본설정없다고 동일하게 나오는것 같다.

DataSource 구성하기
실제 프로젝트에선s H2 DB를 사용한다고 한다. (MemoryDB)
단 메모리 DB 종류 아래와 같이 살짝 체크해보자.
H2 Database
특징
1. 메모리 데이터 베이스 : 주로 테스트 및 개발 전용 사용, 메모리에 데이터 저장
2. 경량/빠른 속도 : 경량의 데이터 베이브로 높은 성능
3. 자체 웹 콘솔 제공 : 웹 기반 콘솔을 제공. 이를 통한 DB 관리 가능
application.yaml 파일 내 아래와 같이 작성 하려고 했는데 프로젝트에는 application.properties 파일이 있다.
이경우는 아래 블로그처럼 refactor를 이용해서 바꿔주면 된다고 한다.
[Spring Boot] 스프링부트 application.yml파일 설정하기 (yml VS properties)
스프링부트 application.yml VS application.properties 이번에는 처음에 스프링부트를 접하면서 application.yml로 설정해놓고 배웠었기에 쭉 사용해왔는데 이번에 기존의application.properties로 설정된 프로젝트
primetime.tistory.com
우선, 스프링부트로 프로젝트를 만들면 기존에 application.properties로 돼있는데 이를 application.yml로 바꾸기 위해서는 Refactor->Rename으로 뒷부분을 yml로 바꿔주면 스프링부트에서 자동으로 yml 형식으로 호환되게끔 바꿔준다.
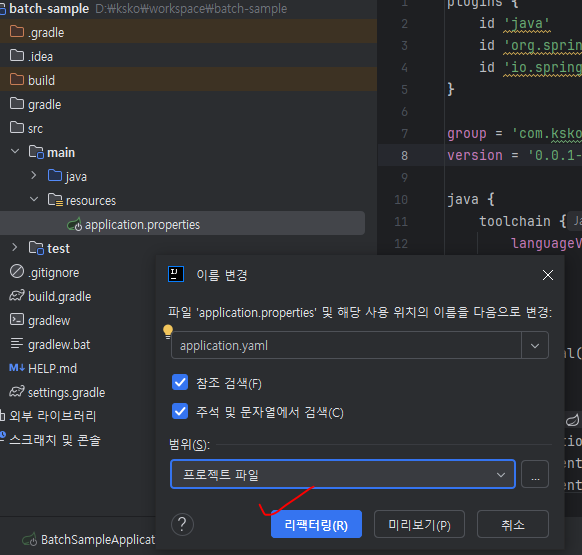
다시 교안에 있는 yaml 파일에 H2 설정파일을 넣어준다.
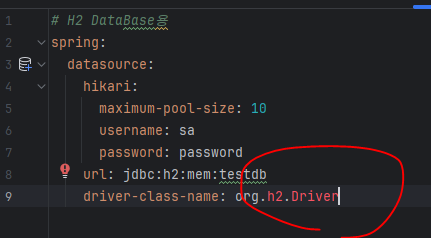
h2 드라이버 인식 못해서 build.gradle에 의존성을 추가하여 빌드 하면 위 빨간 문제가 해결된다.

아래 뭐 뜨지만 일단 무시
HSQL Database
특징
1. 경량 데이터베이스 : 메모리 또는 파일 기반으로 데이터 저장
2. 자바기반 : 100% 자바로 개발된 데이터베이스, java 어플리케이션 내장 데이터베이스로 사용 가능
3. SQL-92 호환 : 표준 SQL 문법 지원
application.yaml 파일 내 아래와 같이 작성
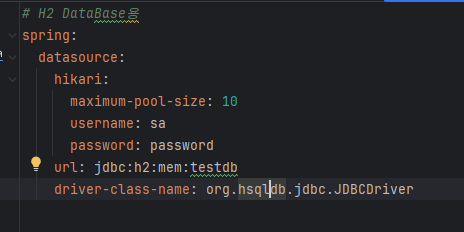
(기존에 작성된 driver-class-name : org.h2.Driver 부분을 삭제하고 다시 작성하는 것 같음)
url: jdbc:hsqldb:mem:testdb
driver-class-name: org.hsqldb.jdbc.JDBCDriver또 빨간색 표기되서, build.gradle 파일에 의존성 파일 추가

다시 gradle 빌드 하면 빨간색 해결됨.
Apache Derby Database
특징
1. 자바 기반 데이터베이스 : Java 어플리케이션 내 내장 데이터베이스로 사용 가능
2. 네트워크 및 임베디드 모드 : 서버모드와 내장(임베디드)를 지원한다.
3. 트랜잭션 지원 : ACID 제공
application.yaml (차이점 부분만)
url: jdbc:derby:memory:testdb;create=true
driver-class-name: org.apache.derby.jdbc.EmbeddedDriver
build.gradle 에
implementation 'org.apache.derby:derby:10.17.1.0'
다시 H2 설정으로 바꾸고 실행하면 정상 접속 확인할 수 있따.

[질문-연재자분께]
Q. DB 관련해서 메모리DB 3종을 다 설명해준 이유가 있는지 궁금하다.
(보통 다른 책들보면 걍 h2 쓴다 하고 끝인데..)
스프링배치 스키마 구조
스프링 배치를 수행하면 자동으로 배치를 위한 DB 스키마가 아래와 같이 생성된다.

참조 : https://docs.spring.io/spring-batch/reference/schema-appendix.html
Meta-Data Schema :: Spring Batch
The Spring Batch Metadata tables closely match the domain objects that represent them in Java. For example, JobInstance, JobExecution, JobParameters, and StepExecution map to BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION, BATCH_JOB_EXECUTION_PARAMS, and BATCH_ST
docs.spring.io
이거 하단 내용은 테이블 관련 상세 설명 내용인데
이 구조에 대해서 어느정도 내가 스스로 각자 학습해야 하므로
블로그상에는 원 교재 안에 있는 내용 복사 붙여넣기 한다.
하지만 H2에서 자동으로 아래 테이블이 자동으로 생성됫는지는 눈으로 확인해보자.
H2 콘솔 붙는법
참고 : https://herojoon-dev.tistory.com/141
Spring Boot에 H2 Database 설정, H2 Console 띄우기
목표 Spring Boot에 H2 Database 설정, H2 Console 띄우기 H2 Database란? : H2는 자바로 작성된 관계형 데이터베이스 관리 시스템입니다. 인메모리 테이블과 디스크 기반 테이블을 둘 다 생성할 수 있습니다.
herojoon-dev.tistory.com
application.yaml 파일 내 h2 콘솔 붙는 방법 확인한다.
우선 build.gradle 내 web 의존성 주입 해주고 gradle 빌드를 다시 해준 뒤 애플리케이션을 실행한다.
implementation 'org.springframework.boot:spring-boot-starter-web'

아... 단순 실행만 한다고, 테이블이 실행되는것이 아닌것 같다.
자동 생성해주지 않는 것 같다.
스프링배치 관련 자동 생성해주는 것 관련 블로그를 찾았다.
참고 : https://madplay.github.io/post/spring-batch-auto-create-metadata-tables
스프링 배치 메타데이터 테이블 자동 생성 설정
스프링 배치(Spring Batch)에서 사용하는 메타데이터(Meta-Data) 테이블을 자동 생성하도록 설정하는 방법
madplay.github.io
참고 : https://curiousjinan.tistory.com/entry/spring-boot-3-batch-5-table-creation-fix
Spring Boot 3 및 Spring Batch 5에서 배치 테이블 자동 생성 문제 해결하기
SpringBoot3에서 배치를 사용할 때 왜 테이블을 자동으로 만들어 주지 않을지 알아보고 이것을 해결해 보자 1. 배치를 사용할 때 자동으로 테이블을 생성해 주지 않는 문제 1-1. 테이블이 생성되지
curiousjinan.tistory.com
참고 : https://soobysu.tistory.com/146
[오류노트] Spring Batch [ Could not obtain sequence value ]
problem Could not obtain sequence value 스프링배치 기능 구현 중 Could not obtain sequence value 에러를 만났다. 환경 - H2 / Spring 3.x 을 사용하고 있었다. solution DB에 Batch 정보를 담는 테이블이 생성되지 않아 발
soobysu.tistory.com
1-1. 테이블이 생성되지 않는 원인 파악하기
- Spring Boot 3에서 Spring Batch를 사용할 때 'application.yml'에 batch.jdbc.initialize-schema: ALWAYS와 job.enabled: true를 설정했는데도 불구하고 자동으로 DB 테이블이 생성되지 않는 문제가 있다. 이 문제의 원인은 Spring Boot 3에서 일부 자동 구성 변경 사항 때문이다.
안되서 수기로 SQL 쿼리에서 insert 하는 것 같다.. 하 그냥 여기까지 하자 ㅠㅠ
===============
BATCH_JOB_INSTANCE Table
- 스키마중 가장 기본이 되는 배치 잡 인스턴스 테이블이다.
- 배치가 수행되면 Job이 생성이 되고, 해당 잡 인스턴스에 대해서 관련된 모든 정보를 가진 최상위 테이블이다.
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_NAME VARCHAR(100) NOT NULL ,
JOB_KEY VARCHAR(32) NOT NULL
);- JOB_INSTANCE_ID: 인스턴스에 대한 유니크 아이디이다. JobInstance 객체의 getId로 획득이 가능하다.
- VERSION: 버젼정보
- JOB_NAME: 배치잡 객체로 획득한 잡 이름이다. 인스턴스를 식별하기 위해 필요하다. 널이 될 수 없다.
- JOB_KEY: JobParameter를 직렬화한 데이터값이며, 동일한 잡을 다른 잡과 구분하는 값이다. 잡은 이 JobParameter가 동일할 수 없으며, JOB_KEY는 구별될수 있도록 달라야한다.
BATCH_JOB_EXECUTION_PARAMS Table
- JobParameter에 대한 정보를 저장하는 테이블이다.
- 여기에는 하나 이상의 key/value 쌍으로 Job에 전달되며, job이 실행될때 전달된 파라미터 정보를 저장하게 된다.
- 각 파라미터는 IDENTIFYING이 true로 설정되면, JobParameter 생성시 유니크한 값으로 사용된경우라는 의미가 된다.
- 테이블은 비정규화 되어 있고, 구조는 다음과 같다.
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
PARAMETER_NAME VARCHAR(100) NOT NULL ,
PARAMETER_TYPE VARCHAR(100) NOT NULL ,
PARAMETER_VALUE VARCHAR(2500) ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);- JOB_EXECUTION_ID: 잡 실행 아이디이며 이것은 BATCH_JOB_EXECUTION으로 부터 온 외래키이다. 각 실행마다 여러 행(키/값) 이 저장된다.
- PARAMETER_NAME: 파라미터 이름
- PARAMETER_TYPE: 파라미터의 타입
- PARAMETER_VALUE: 파라미터 값
- IDENTIFYING: 파라미터가 JobInstance의 유니크성을 위해 사용된 파라미터라면 true로 세팅된다.
- 이 테이블에는 기본키가 없다.
BATCH_JOB_EXECUTION Table
- JobExecution과 관련된 모든 정보를 저장한다.
- Job이 매번 실행될때, JobExecution이라는 새로운 객체가 있으며, 이 테이블에 새로운 row로 생성이 된다.
- 다음은 테이블 구조이다.
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(20),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;- JOB_EXECUTION_ID: 배치자 실행 아이디, 실행을 유니크하게 구분할 수 있다. 칼럼의 값은 JobExecution 의 getId메소드로 획득이 가능하다.
- VERSION: 버젼정보
- JOB_INSTANCE_ID: BATCH_JOB_INSTANCE 테이블의 기본키로 외래키이다. 이는 execution이 소속된 인스턴스가 된다. 하나의 인스턴스에는 여러 execution이 있을 수 있다.
- CREATE_TIME: execution이 생성된 시간이다.
- START_TIME: execution이 시작된 시간이다.
- END_TIME: execution이 종료된 시간이다. 성공이든 실패든 남게된다. 잡이 현재 실행중이 아닐때 열의 값이 비어 있다면, 특정 유형의 오류가 발생하여 프레임워크가 실패하기전 마지막 저장을 수행할 수 없음을 나타낸다.
- STATUS: execution의 현재 상태를 문자열로 나타낸다. COMPLETED, STARTED 및 기타, 이는 BatchStatus 나열값으로 채워진다.
- EXIT_CODE: execution의 종료 코드를 문자열로 나타낸다. 커맨드라인 잡의 케이스에서는 숫자로 변환된다.
- EXIT_MESSAGE: job이 종류되는 경우 어떻게 종료되었는지를 나타낸다. 가능하다면 stack trace값이 남게 된다.
- LAST_UPDATED: execution이 마지막으로 지속된 시간을 나타내는 타임스탬프이다.
BATCH_STEP_EXECUTION Table
- BATCH_STEP_EXECUTION Table 은 StepExecution과 관련된 모든 정보를 가진다.
- 이 테이블은 여러 면에서 BATCH_JOB_EXECUTION 테이블과 유사하며 생성된 각 JobExecution에 대한 단계당 항목이 항상 하나 이상이 있다.
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL ,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(20) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP,
constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;- STEP_EXECUTION_ID: execution에 대해 유니크한 아이디이다. 이 칼럼은 StepExecution 객체의 getId를 통해 조회가 가능하다.
- VERSION: 버젼정보
- STEP_NAME: execution이 귀속된 스텝의 이름이다.
- JOB_EXECUTION_ID: BATCH_JOB_EXECUTION 테이블에 대한 외래키이다. 이는 JobExecution에 StepExecution이 속한다 의미이다. JobExecution에 대해 Step 이름은 유니크해야한다.
- START_TIME: execution이 시작된 시간을 나타낸다.
- END_TIME: execution이 종료된 시간을 나타낸다. 현재 수행하지 않는데 이 값이 비어있다면, 에러가 발생했거나, 실패하기 전에 마지막 실패전 작업이 저장되지 않았음을 의미한다.
- STATUS : execution의 상태를 표현한다. COMPLETED, STARTED 와 기타 정보가 된다. 이는 BatchStatus 에 대한 나열값으로 표현할 수 있다.
- COMMIT_COUNT: execution동안 트랜잭션 커밋된 카운트를 나열한다.
- READ_COUNT: 이 실행된 동안 읽어들인 아이템 수
- FILTER_COUNT: 이 실행동안 필터된 아이템수
- WRITE_COUNT: 이 실행동안 쓰기된 아이템수
- READ_SKIP_COUNT: 이 실행동안 읽기시 스킵된 아이템수
- WRITE_SKIP_COUNT: 이 실행동안 쓰기가 스킵된 아이템수
- PROCESS_SKIP_COUNT: 이 실행동안 프로세서가 스킵된 아이엠
- ROLLBACK_COUNT: 이 실행동안 롤백된 아이템수, 재시도를 위한 롤백과 복구 프로시저에서 발생한 건을 저장한다.
- EXIT_CODE: 이 실행동안 종료된 문자열이다. 커맨드라인 잡이라면 이 값은 숫자로 변환된다.
- EXIT_MESSAGE: job이 종류되는 경우 어떻게 종료되었는지를 나타낸다. 가능하다면 stack trace값이 남게 된다.
- LAST_UPDATED: execution이 마지막으로 지속된 시간을 나타내는 타임스탬프이다.
BATCH_JOB_EXECUTION_CONTEXT Table
- Job의 ExecutionContext 에 대한 모든 정보를 저장한다.
- 이것은 매 JobExecution마다 정확히 하나의 JobExecutionContext를 가진다. 여기에는 특정 작업 실행에 필요한 모든 작업 수준 데이터가 포함되어 있다.
- 이 데이터는 일반적으로 실패 후 중단된 부분부터 시작될 수 있도록 실패후 검색해야하는 상태를 나타낸다.
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;- JOB_EXECUTION_ID: job execution 테이블에 대한 아이디로 외래키이다. 여기에는 주어진 execution마다 여러개의 row가 쌓인다.
- SHORT_CONTEXT: SERIALIZED_CONTEXT 의 문자로된 버젼이다.
- SERIALIZED_CONTEXT: 직렬화된 전테 컨텍스트이다.
BATCH_STEP_EXECUTION_CONTEXT Table
- BATCH_STEP_EXECUTION_CONTEXT 테이블은 Step의 ExecutionContext 과 관련된 모든 정보를 가진다.
- StepExecution 마다 정확히 하나의 ExecutionContext 이 있다. 그리고 특정 step execution 에 대해서 저장될 필요가 있는 모든 데이터가 저장된다.
- 이 데이터는 일반적으로 JobInstance가 중단된 위치에서 시작 할 수 있도록 실패 후 검색해야 하는 상태를 나타낸다.
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;- STEP_EXECUTION_ID: StepExecution의 키로 외래키이다 여기에는 주어진 execution에 연관된 모든 row가 존재한다.
- SHORT_CONTEXT: SERIALIZED_CONTEXT 의 문자로된 버젼이다.
- SERIALIZED_CONTEXT: 직렬화된 전테 컨텍스트이다.
SpringBatch Sequences
- 스프링배치는 기본적으로 시퀀스 테이블이 존재한다.
BATCH_JOB_SEQ
- 배치 잡에 대한 시퀀스 테이블이다.
- ID:
- bigint
- 배치 잡의 기본키를 나타낸다.
- UNIQUE KEY
- char(1)
- 배치잡 시퀀스를 구별하는 유니크 PK
BATCH_JOB_EXECUTION_SEQ
- 배치잡 execution의 시퀀스 테이블이다.
- ID:
- bigint
- 배치 잡 execution 의 기본키를 나타낸다.
- UNIQUE KEY
- char(1)
- 배치잡 execution 시퀀스를 구별하는 유니크 PK
BATCH_STEP_EXECUTION_SEQ
- 배치 스텝의 execution 시퀀스 테이블이다.
- ID:
- bigint
- 배치 스텝 execution 의 기본키를 나타낸다.
- UNIQUE KEY
- char(1)
- 배치 스텝 execution 시퀀스를 구별하는 유니크 PK
- 위 시퀀스를 통해서 Batch_Job_Instance, Batch_Execution, Batch_Step_Execution 의 시퀀스를 배치가 할당하며, 이 값은 중복될 수 없다.
WrapUp
- 지금까지 작업으로 스프링 배치를 위한 가장 기본적인 설정을 해 보았다.
- 스프링 배치는 자체 배치 작업을 수행하기 위해서 데이터베이스가 필요하고
- @EnableBatchProcessor 를 설정하면 실행될때 배치를 위한 테이블이 자동으로 생성이 된다.
- 자동으로 생성된 각 테이블을 살펴 보았고, 어떠한 데이터가 저장되는지 확인할 수 있었다.
'개발 > 02-1.Spring Batch' 카테고리의 다른 글
| [SpringBatch, DEVOCEAN] Week7- (EZ하게) MyBatisPagingItemReader로 DB내용을 읽고, MyBatisItemWriter로 DB에 쓰기 (2) | 2024.11.19 |
|---|---|
| [SpringBatch, DEVOCEAN] Week5-JdbcPagingItemReader로 DB내용을 읽고, JdbcBatchItemWriter로 DB에 쓰기 (3) | 2024.11.06 |
| [SpringBatch, DEVOCEAN] Week2 - SpringBatch 코드 설명 및 아키텍처 알아보기 (미완성) (1) | 2024.10.15 |
| [SpringBatch,참고] 보조 공부자료 (cheeseyun10) (1) | 2024.09.02 |
| [Spring Batch] 시작해보자. (0) | 2024.08.20 |

